Implementing AI Chatbot


Last week I discovered very helpful software for building any AI integrations.
“The Vercel AI SDK is an open-source library designed to help developers build conversational, streaming, and chat user interfaces in JavaScript and TypeScript. The SDK supports React/Next.js, Svelte/SvelteKit, with support for Nuxt/Vue coming soon.”
Vercel offers different guides and tutorials, which combine code with technologies like:
- Hugging face,

- Langchain,
 langchain-ai
langchain-ai- Perplexity,
- And more.
Let's go with a next.js 14 example:
"Below is a minimal route handler for using the OpenAI Chat API with the openai API client and the Vercel AI SDK."
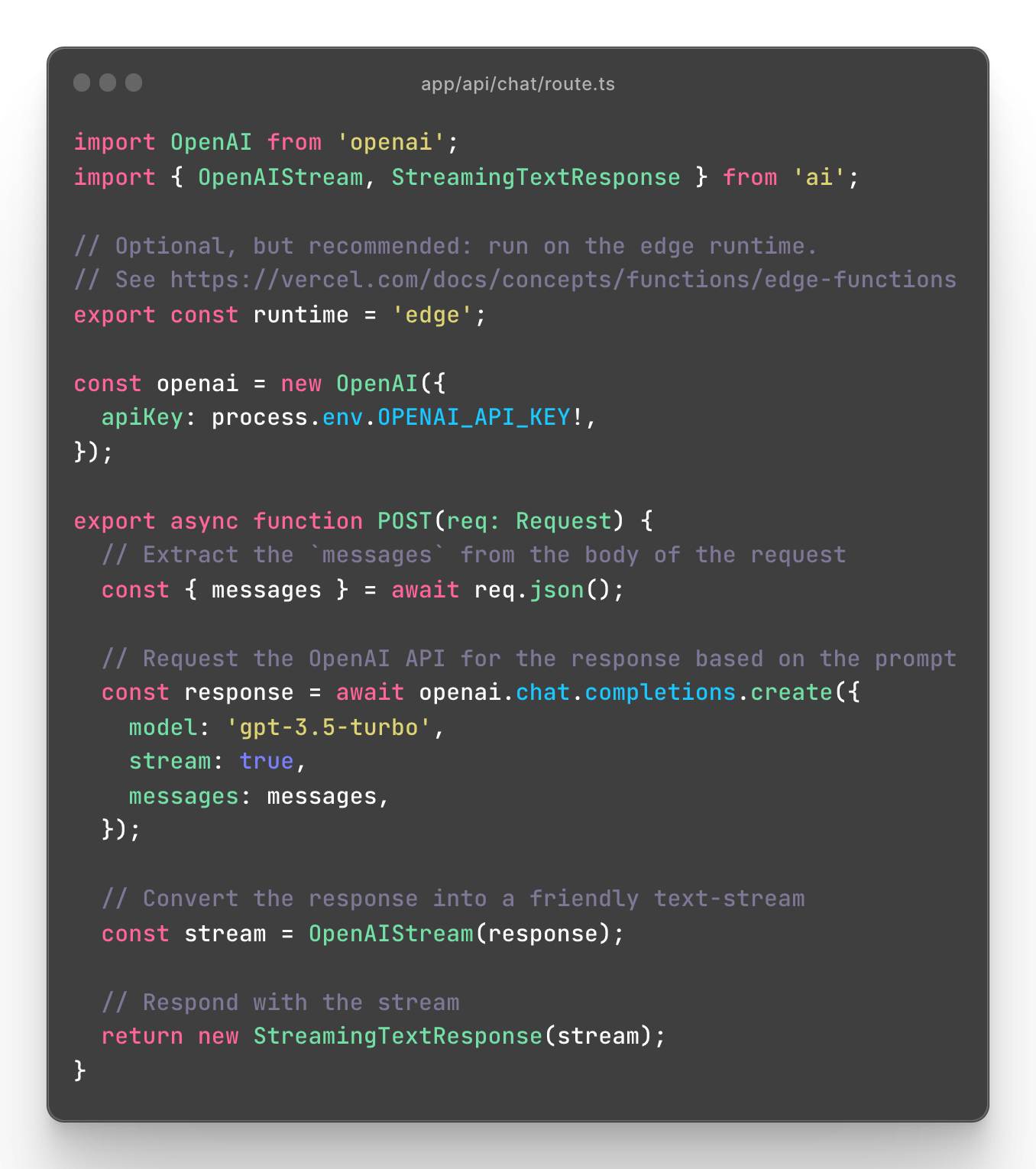
"The Route Handler code can be adapted to work with Server Components(opens in a new tab), but additional work needs to be done to render the stream as it comes in. The provided example is a proof-of-concept."
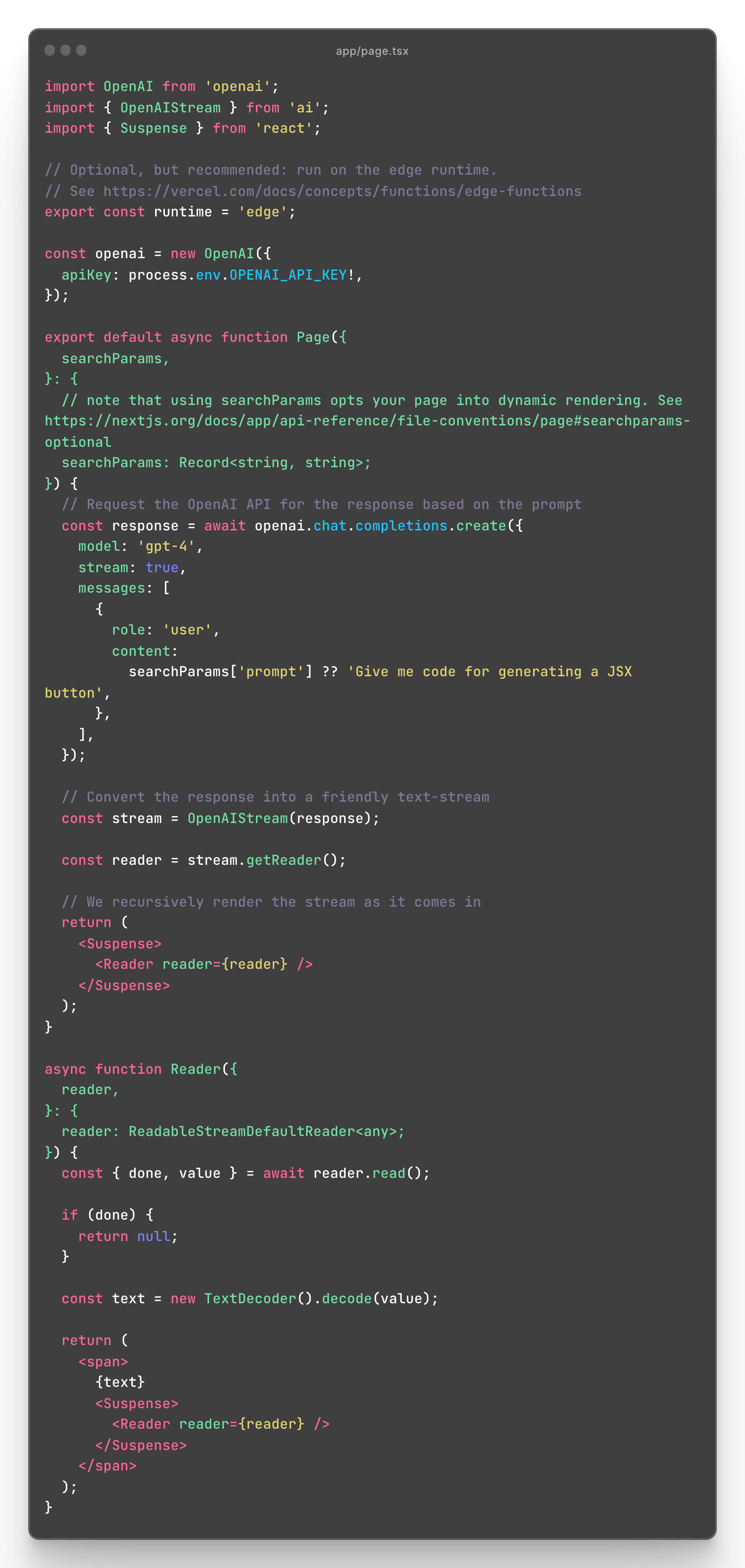
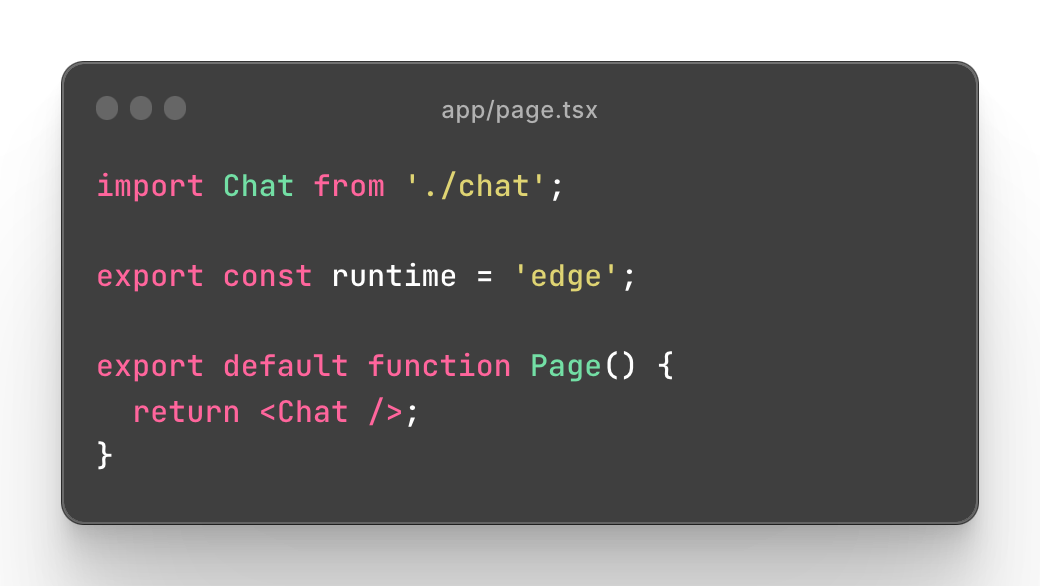
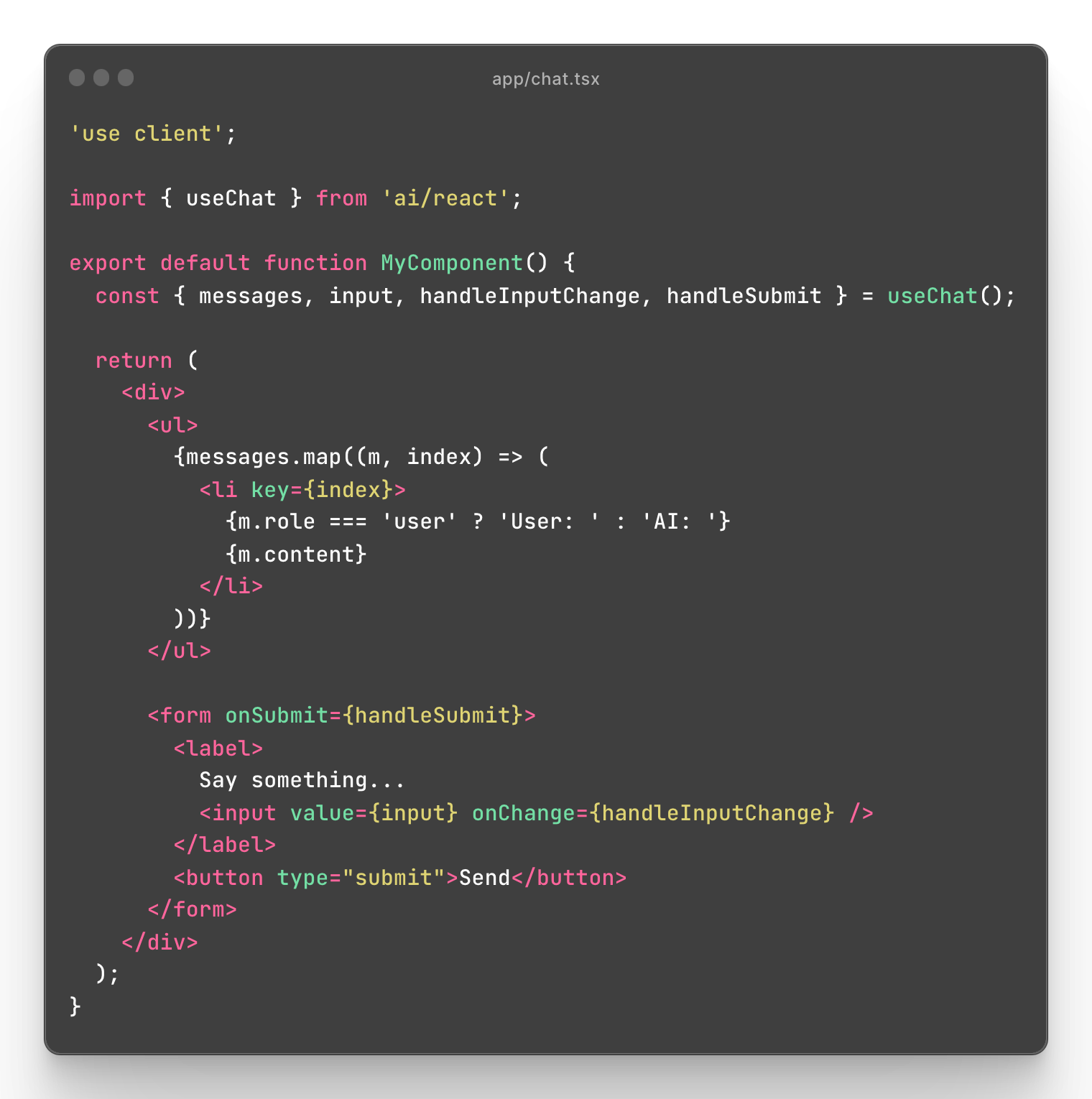
"You can use the SDK's useChat and useCompletion hooks inside of Client Components. However, you cannot set a routes runtime from them, so if you want to opt-in to the Edge runtime you should create a wrapper React Server Component like so:"
You can view my latest video about basic setup, in 3 min:
GitHub repo with code:
Kacper-HernackiHow do we connect it with memory? | qdrant vector database
Such an implementation is not providing extra value, but we can scale it, by adding the "memory".
Generally speaking, memory should be easily accessible by the chat, it can be achieved by vector database and embeddings. Let's explain what they are:
A vector database is a special kind of database used for storing and working with vectors, which are just lists of numbers. These vectors help computers understand and search through complex data like pictures, text, or sounds.
Embedding is a way to turn this complex data (like words or images) into those vectors. Imagine it like taking a big, complicated idea and shrinking it down into a simple, small list of numbers, but in a way that keeps all the important stuff about the idea. This makes it easier for computers to see how different pieces of data are similar to each other.
Knowing that we can show how easily it can be implemented in a chatbot with memory.
Qdrant Vector Database in Next.js

Let's use Qdrant as a vector database in the project.
To have it started, we should have docker run on our machine.
Then let's pull the image of qdrant and run the container.

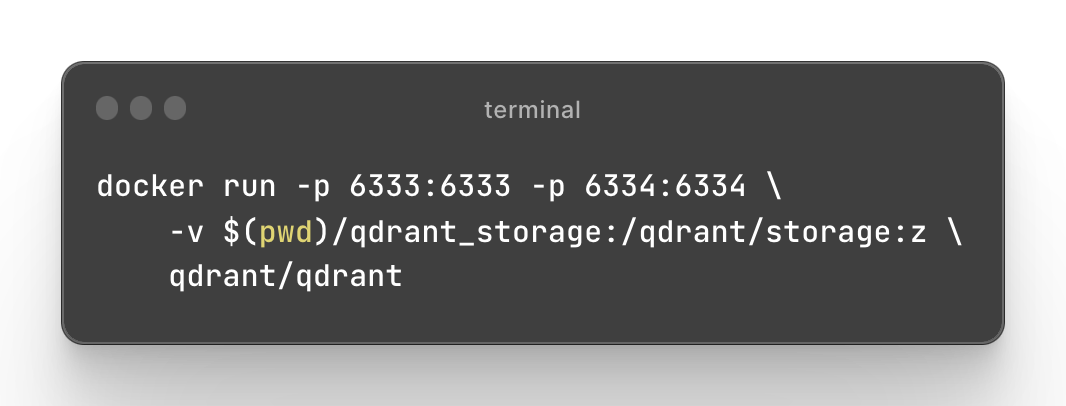
Qdrant is now accessible:
- REST API: localhost:6333
- Web UI: localhost:6333/dashboard
- GRPC API: localhost:6334
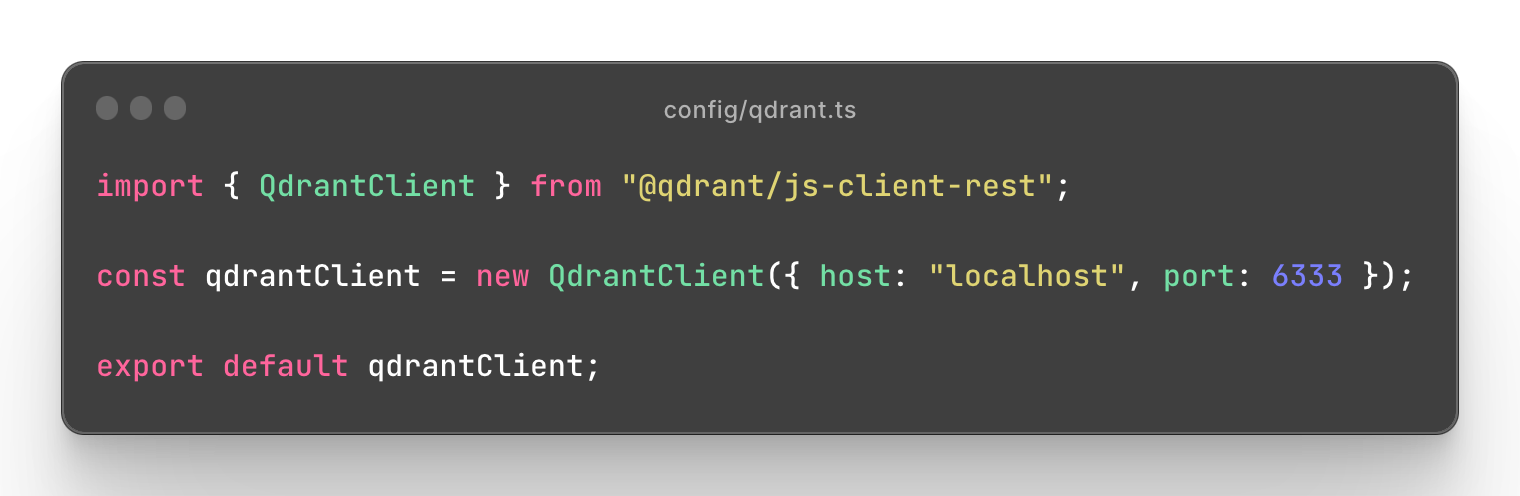
Now you can initialize qdrant client in a project.
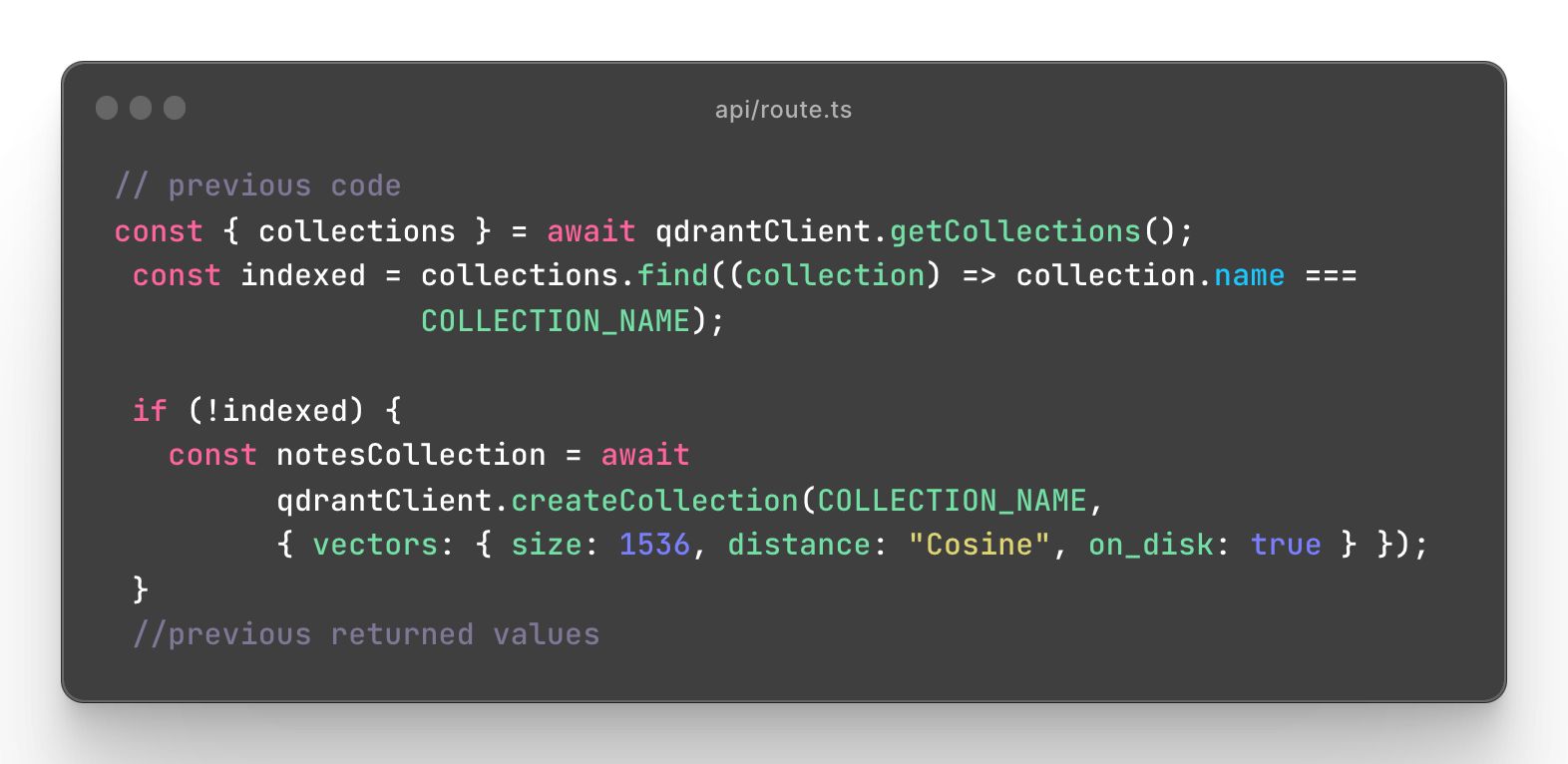
then we can create a new collection in a database. Let's store the name of a collection in a variable "COLLECTION_NAME".
(The choice of a vector size of 1536 and the use of cosine similarity for measuring distances between vectors in machine learning, especially in the context of natural language processing (NLP) and embedding models, is based on a balance between computational efficiency and the ability to capture sufficient information about the data.)
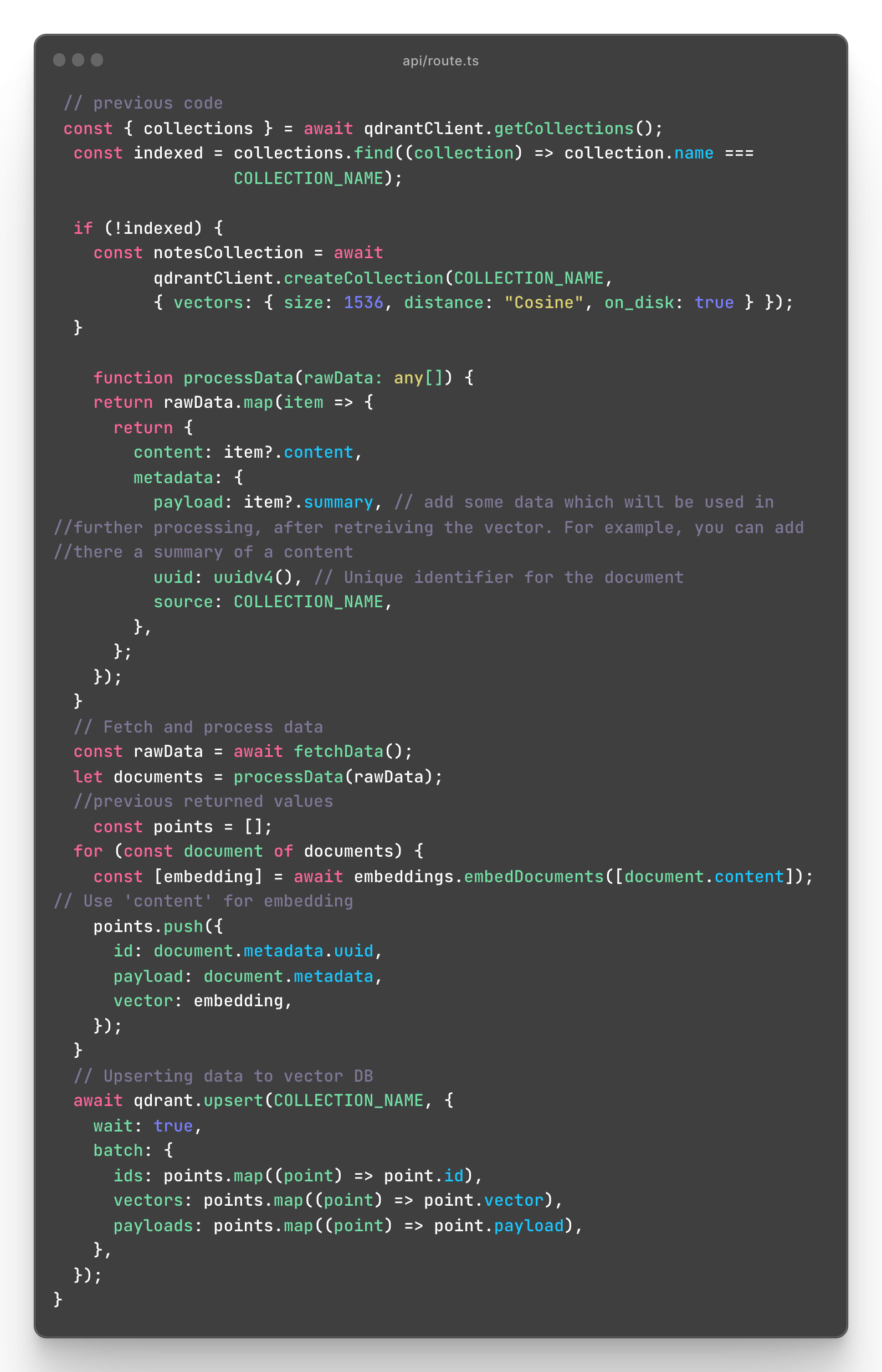
Let's continue with qdrant.
We have created a new collection, now we can add there some data.
Before adding data, it is needed to process it, as you can see in the processData function, fetched rawData, are being processed to return content and the metadata.
Then documents (processed Data) are proceeded into points, each point receives an embedding as a vector.
Embedding is returned from processing the content of a document.
At the last step, such points are inserted into the database.
Do you have more questions? Join the moderndev discord channel and ask a question.
How to retrieve the data in a question?
To get a response we can use the question parameter, which you can provide to an endpoint, and then make embedding of it.
Thanks to similarity search, qdrant will return the vector which is the most similar for the question.
Then entire response can be edited by chatGPT and responded in any way you want.

TalkingNotes
By expanding presented above methods, I decided to make a product that can revolutionize the noting.
Simple AI Chatbot that can be embeddable in notion as an assistant, who has a knowledge of the content of your note.
Sounds crazy?
I am testing my MVP and preparing for the launch. You can see the preview below:
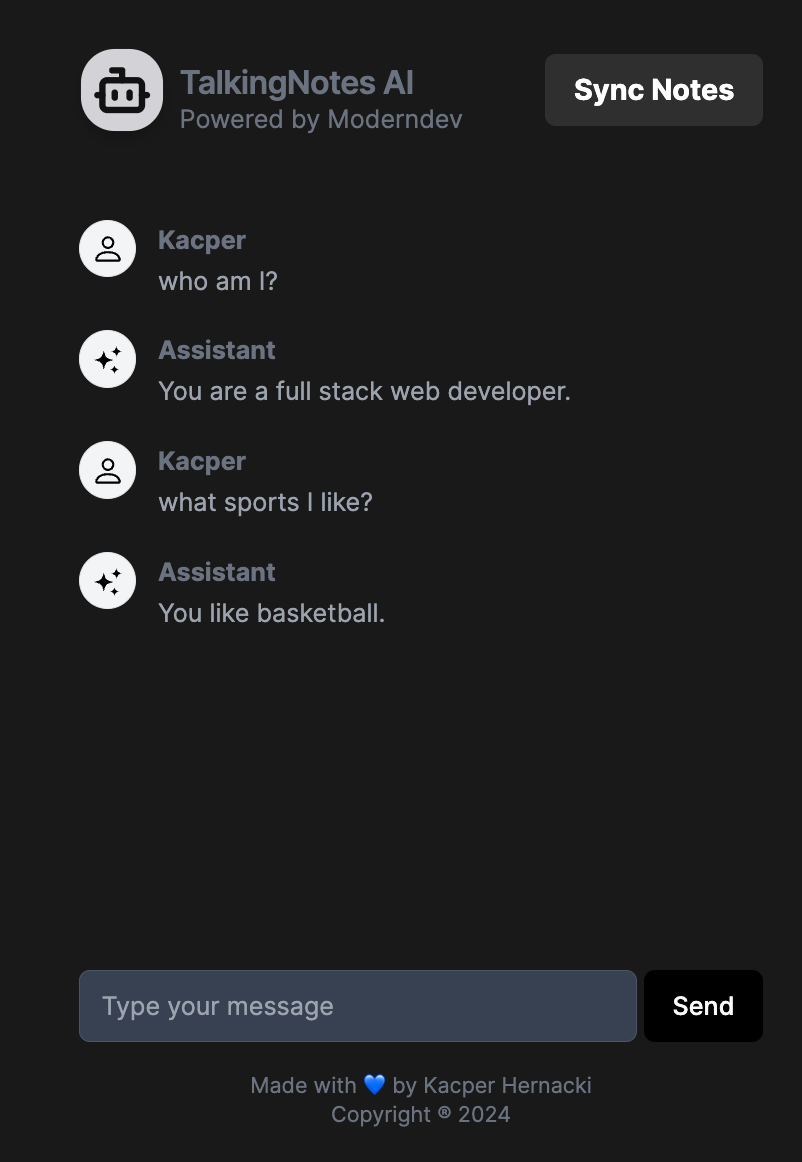
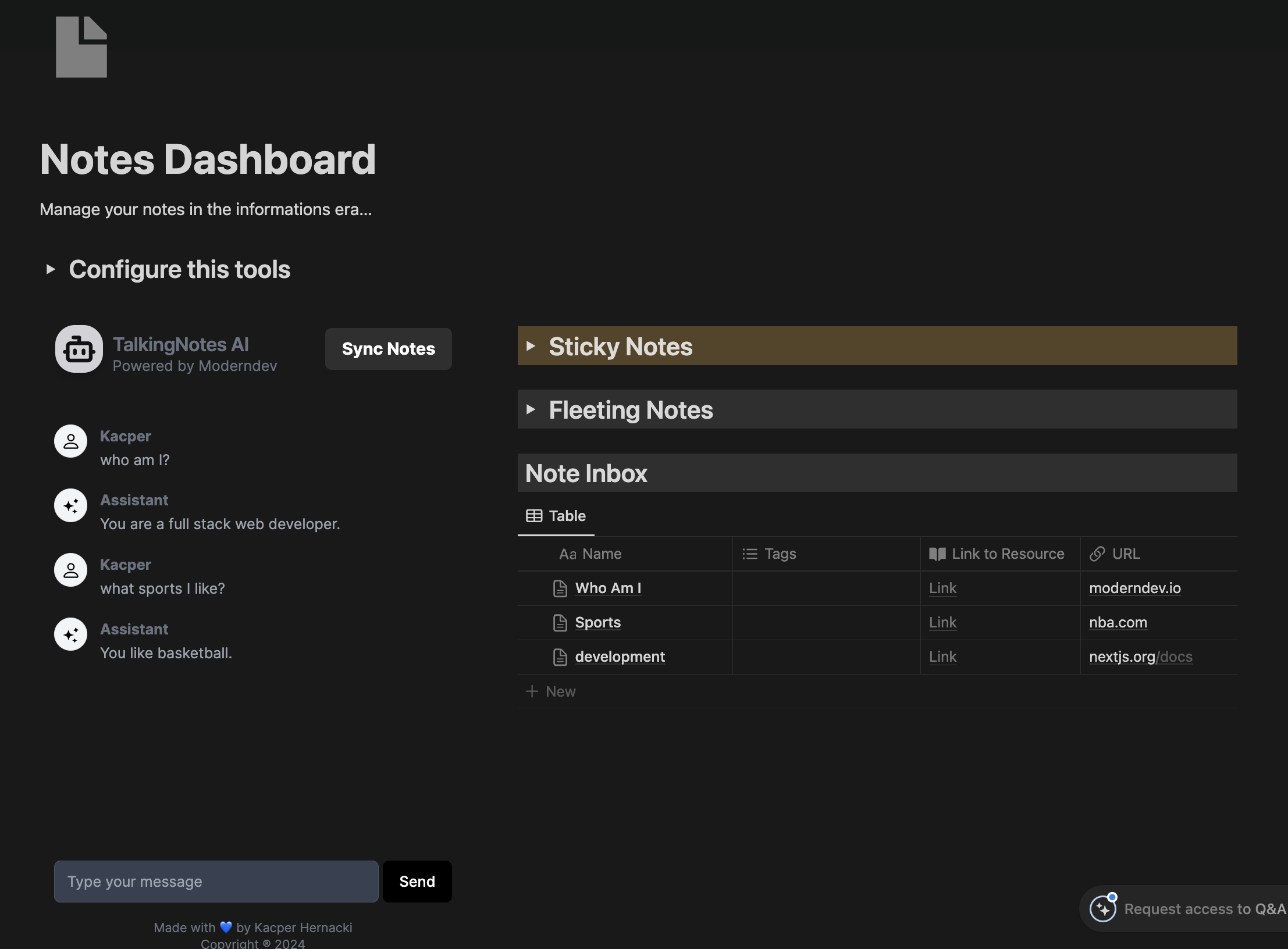
Would you like to have access as an early bird? Soon I start with a waitlist.
Tweet of the week
I shipped 17 startups in 2 years because I gamified the process:
— Marc Lou (@marc_louvion) December 11, 2023
- Build in 14 days max
- Launch with a fun video
- Talk about it on Twitter
You can't give up if you're having fun. pic.twitter.com/ObPgtSts85
Book of the week

"The Bitcoin Standard" by Saifedean Ammous is a comprehensive exploration of the history of money, the role of Bitcoin as a new form of money, and its potential to become a global monetary standard.
I really enjoyed reading this book, cause there is literally a knowledge that nobody teaches.
You can learn how our financial system is bad and how it has changed over the years.



